BR Algorithms Corner
Re: BR Algorithms Corner
In fact Shor's algorithm is the first one for which he won the Nevanlinna prize.
Re: BR Algorithms Corner
SaiK: Urbana was much better before. After several theoreticians left (or retired), it's rankings went down somewhat. Now there are a set of really bright young faculty.
Re: BR Algorithms Corner
the qft wiki linked KR Parthasarathy
Kostant–Parthasarathy–Ranga Rao–Varadarajan determinants
http://en.wikipedia.org/wiki/Kostant%E2 ... terminants
nothing available in details.
just fyi, having seen some indic names
-------------------
http://beust.com/algorithms.pdf
Kostant–Parthasarathy–Ranga Rao–Varadarajan determinants
http://en.wikipedia.org/wiki/Kostant%E2 ... terminants
nothing available in details.
just fyi, having seen some indic names
-------------------
http://beust.com/algorithms.pdf
Re: BR Algorithms Corner
Saik : thanks. Nice book that by papadimitrou and umesh vazirani. Scott aronson of MIT is a student of the latter and U.S. considered the guru of quantum computing currently. He is also on the committee of clay institute which has seven milinennium problems the solutions if which carry a one million dollar award each.
Re: BR Algorithms Corner
hats off math guru.. I wish I can do a dump from your matrix information. I can't keep up names even some people I have worked close from last few jobs.
Re: BR Algorithms Corner
Continuing on ArmenT's problem, if the min and max keys are known and the key distribution is uniform, an O(n^1.5) algorithm is possible.
Think of a pointer array sqrt(n) long where each ement of the array points to a at most sqrt(n) long array. Each insertion can be done in O(sqrt(n)), O(1) to jump to the array into which the input number has to be inserted, O(sqrt(n)) to make space and insert. Since there are n input keys, one ends up with a O(n^1.5) for all insertions. This will also beat the O(n^2) algorithm quite handily and is almost as simple.
For deletions, one needs to maintain another field along with the pointer which gives how many elements are there in the array that is pointed to by the corresponding pointer. Then each deletion by rank is also takes O(sqrt(n)). So O(n) deletions will take O(n^1.5).
Total algorithm will then be O(n^1.5).
If the input data distribution is known, there are some clever algorithms based on radix/bucket sort which will give O(n) under some reasonable computational model assumptions. Reasonable in the sense that they are physically realizable/existent.
Think of a pointer array sqrt(n) long where each ement of the array points to a at most sqrt(n) long array. Each insertion can be done in O(sqrt(n)), O(1) to jump to the array into which the input number has to be inserted, O(sqrt(n)) to make space and insert. Since there are n input keys, one ends up with a O(n^1.5) for all insertions. This will also beat the O(n^2) algorithm quite handily and is almost as simple.
For deletions, one needs to maintain another field along with the pointer which gives how many elements are there in the array that is pointed to by the corresponding pointer. Then each deletion by rank is also takes O(sqrt(n)). So O(n) deletions will take O(n^1.5).
Total algorithm will then be O(n^1.5).
If the input data distribution is known, there are some clever algorithms based on radix/bucket sort which will give O(n) under some reasonable computational model assumptions. Reasonable in the sense that they are physically realizable/existent.
Re: BR Algorithms Corner
The structure you are describing is actually similar to how hash tables are implemented in several environmentsmatrimc wrote: Think of a pointer array sqrt(n) long where each ement of the array points to a at most sqrt(n) long array. Each insertion can be done in O(sqrt(n)), O(1) to jump to the array into which the input number has to be inserted, O(sqrt(n)) to make space and insert. Since there are n input keys, one ends up with a O(n^1.5) for all insertions. This will also beat the O(n^2) algorithm quite handily and is almost as simple.
Re: BR Algorithms Corner
The problem is to find a hash function which has a range which is uniformly distributed if the domain is uniformly distributed.
Re: BR Algorithms Corner
surjective?
Re: BR Algorithms Corner
ArmenT, the problem you posted requires maintaining order. A hash table won't do that.
Depending on WHY order is needed, there might be other ways to do it.
Depending on WHY order is needed, there might be other ways to do it.
Re: BR Algorithms Corner
^ I posted about augmenting balanced binary trees which can achieve O(lg n) for each insert and delete by rank. I think that is final - none can do better sans information about input data.
Re: BR Algorithms Corner
there is also Sorted Map.
Re: BR Algorithms Corner
I think ArmenT was simply pointing out hashing but not a solution to the problem he posted. My reply regarding hashing is also not related to his problem but a general comment which I am expanding below.
Basically if one knows the domain and the domain is a finite set with cardinality N, the hash function is an identity map with finding an element a O(N) operation.
The other method is to as a pre-processing step, (increasing or decreasing) sort all the elements in the domain (caveat being that the elements in the domain have an ordering relation, i.e. loosely every pair is comparable and using a relation like <, they can be put into one-to-one correspondence with integers) which has a lower bound of O(N log N) and can be achieved by various algorithms including Binary search trees or priority queues. The hash function is a binary search each application of which takes O(log N).
The above two will work if the application calls for an off-line algorithm. An off-line algorithm has all the data known before hand (before even pre-processing). If the application calls for an on-line algorithm then the input data is not known before hand. There are two cases.
case 1: only the lower and upper bounds are known and the input data is of the size O(N) where N = upper - lower + 1; then we can use the augmenting balanced BST (AVL or red-black or other variations of balanced BSTs since we need to bound the height of the search tree).
case 2: Nothing is known about the data.
Now case 2 arises in off-line algorithms too if the domain is much larger than what can be stored on the computer (including secondary memory like hard disks, robot tapes etc.) yet the input data size N << domain cardinality.
This is when a hash function is useful in that hash function can handle this most general case. Only problem is that it may not work efficiently in that collisions may result in large subsets of the input data (define large as O(N)) map to the same number in the range. In this case, every collision resolution strategy I know of takes at least O(log N) and at most O(N) for each querying.
For example the pathological case is the hash function h:x -> 1.
Every element x in the input stream is mapped to the value 1.
One collision resolution scheme is to keep the input data as a list (linked list or array does not matter). Then each query takes O(N).
Another is what I proposed, i.e. a balanced BST in which case each quesry takes O(lg N) which follows from the properties of balanced BSTs.
The point is that the hash function needs to map a larger set to a smaller set. From pigeon hole principle, collisions will be there.
If one is talking input data size much smaller than memory on the computer, then what difference does it make if the algorithm runs in O(N^2) or O(N lg N) if the latter has large constants hidden in the big O notation? If one is not pushing the limits, it is all moot. This is the case with most GUI/games/office applications like word processing or IO bound processing.
By the way, on-line algorithms should not be confused with either on-line Information Processing nor with real-time systems.
Basically if one knows the domain and the domain is a finite set with cardinality N, the hash function is an identity map with finding an element a O(N) operation.
The other method is to as a pre-processing step, (increasing or decreasing) sort all the elements in the domain (caveat being that the elements in the domain have an ordering relation, i.e. loosely every pair is comparable and using a relation like <, they can be put into one-to-one correspondence with integers) which has a lower bound of O(N log N) and can be achieved by various algorithms including Binary search trees or priority queues. The hash function is a binary search each application of which takes O(log N).
The above two will work if the application calls for an off-line algorithm. An off-line algorithm has all the data known before hand (before even pre-processing). If the application calls for an on-line algorithm then the input data is not known before hand. There are two cases.
case 1: only the lower and upper bounds are known and the input data is of the size O(N) where N = upper - lower + 1; then we can use the augmenting balanced BST (AVL or red-black or other variations of balanced BSTs since we need to bound the height of the search tree).
case 2: Nothing is known about the data.
Now case 2 arises in off-line algorithms too if the domain is much larger than what can be stored on the computer (including secondary memory like hard disks, robot tapes etc.) yet the input data size N << domain cardinality.
This is when a hash function is useful in that hash function can handle this most general case. Only problem is that it may not work efficiently in that collisions may result in large subsets of the input data (define large as O(N)) map to the same number in the range. In this case, every collision resolution strategy I know of takes at least O(log N) and at most O(N) for each querying.
For example the pathological case is the hash function h:x -> 1.
Every element x in the input stream is mapped to the value 1.
One collision resolution scheme is to keep the input data as a list (linked list or array does not matter). Then each query takes O(N).
Another is what I proposed, i.e. a balanced BST in which case each quesry takes O(lg N) which follows from the properties of balanced BSTs.
The point is that the hash function needs to map a larger set to a smaller set. From pigeon hole principle, collisions will be there.
If one is talking input data size much smaller than memory on the computer, then what difference does it make if the algorithm runs in O(N^2) or O(N lg N) if the latter has large constants hidden in the big O notation? If one is not pushing the limits, it is all moot. This is the case with most GUI/games/office applications like word processing or IO bound processing.
By the way, on-line algorithms should not be confused with either on-line Information Processing nor with real-time systems.
Re: BR Algorithms Corner
Java question: we have bitwise shift ops on int. but not on long, and it loses precision on casting or can't perform on long.
how do we do a 64 bit wise shift?
1L << 64L ?
need: i want masking for long.
=========
ps:
i got the answer
http://stackoverflow.com/questions/9880 ... ted-result
Re: BR Algorithms Corner
Following up on my post above SaiK's two posts: This structure is called a van Emde Boas Tree or vEb Tree for short. I found a link which I will post soon.
Re: BR Algorithms Corner
Is this related to this thread?
http://symbolaris.com/info/KeYmaera.html
Can some math mullah/guru give some heads up?
http://symbolaris.com/info/KeYmaera.html
Can some math mullah/guru give some heads up?
Re: BR Algorithms Corner
vayu bhagwan, you might like this
http://www.bzarg.com/p/how-a-kalman-fil ... -pictures/
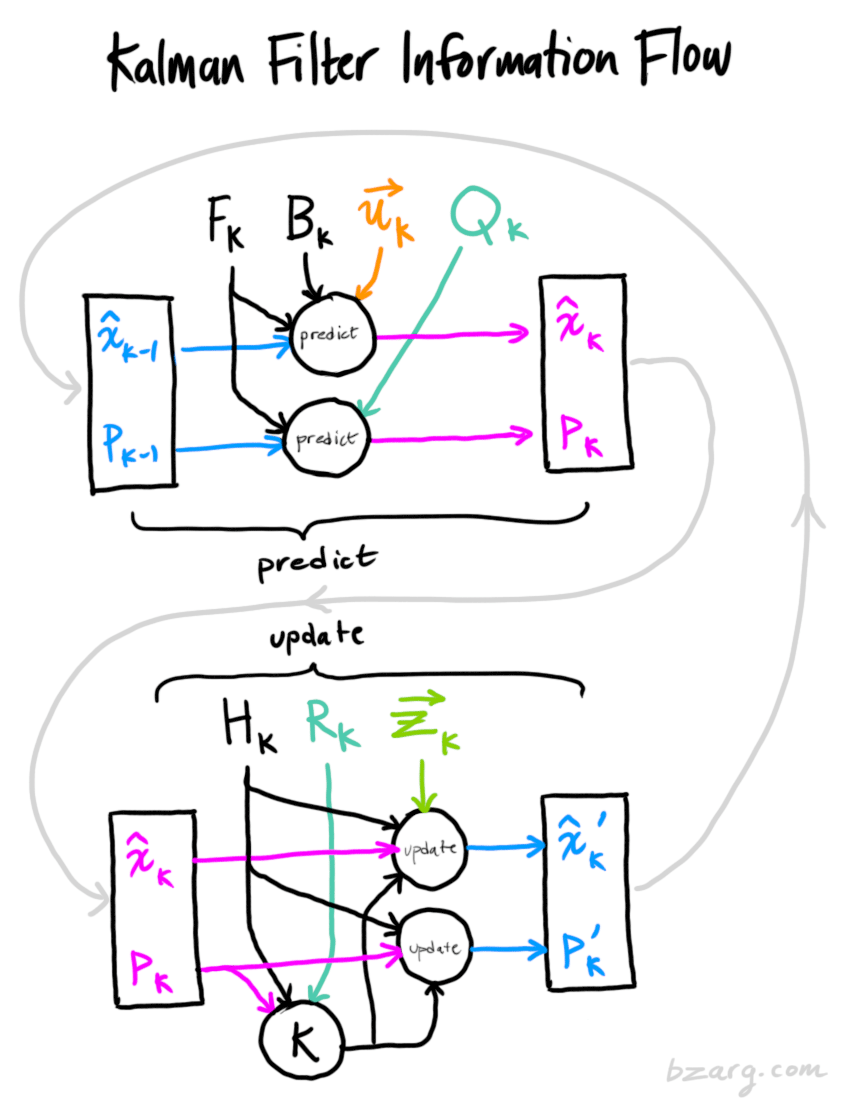
website uses mathml code
now, here is an assignment for you -
pliss to educate me/us on this.
http://www.bzarg.com/p/how-a-kalman-fil ... -pictures/
website uses mathml code
now, here is an assignment for you -
pliss to educate me/us on this.
Re: BR Algorithms Corner
premise:
if all M are P
some S are M
conclusion:
some S are P?
Q:
I am thinking there exists no S in P case too. wrong?
if all M are P
some S are M
conclusion:
some S are P?
Q:
I am thinking there exists no S in P case too. wrong?
Re: BR Algorithms Corner
If S is a singleton set and some means $\exists s \in S and s is M$. Does your word "some" means at least one or it could be zero also?
$\exists$ (E turned left to right, which is also written in ASCII as E) and $\forall$ is upside down A and written A in ASCII.
If you talk sets here, i.e. M P and S are sets say.
if (M \subset P AND intersection of S and M is not empty) then intersection of S and P is not empty.
$\exists$ (E turned left to right, which is also written in ASCII as E) and $\forall$ is upside down A and written A in ASCII.
If you talk sets here, i.e. M P and S are sets say.
if (M \subset P AND intersection of S and M is not empty) then intersection of S and P is not empty.
Re: BR Algorithms Corner
that was my difficulty in understanding hoare's slide from his aristotle/euclid lecture. i assumed some to be >0. given my logical understanding, a zero can't be qualified in 'some'. he had converted on his syllogism to a venn dig. hence my question. when venn of S falls inside M which is covered by P, and some S lying outside P, there was the diagram exposing S in P as well. but, the premise did not say that.
ps: here
http://www.heidelberg-laureate-forum.or ... y-r-hoare/
ps: here
http://www.heidelberg-laureate-forum.or ... y-r-hoare/
Re: BR Algorithms Corner
Hi chilarai- As promised I am putting this here ..Hope this makes some sense.,,
(For those who are unfamiliar with our discussion please see the background at the end of my post)
***
Assume in your loop (original logic), let a=1000, b=1000 and you want to test *all* values of c.
In your method, you have to go from 1 (or 1000 if you assume c>=b>=a) to a*b or about 1000*1000
values (about 999000 iteration if you start from 1000). so for that particular value alone, you are checking a number is a power of two about 1000000 times...
Now, how about just let k for 1 to 20 (so 2^k is already > 1000000), and calculate c, (2^k-ab) and check for only those 20 values of c.. (instead of 999000) times...
I will stop here (as obviously there can be more improvement).. but this is just a VERY small change ib
algorithm.. which improves the through about 50,000 times faster.. (*** Much Much faster in case where you reached say a=1000,000... in this case just this small change will improve 100 BILLION times!)
*** Background ***
Hope this helps.
(For those who are unfamiliar with our discussion please see the background at the end of my post)
***
Assume in your loop (original logic), let a=1000, b=1000 and you want to test *all* values of c.
In your method, you have to go from 1 (or 1000 if you assume c>=b>=a) to a*b or about 1000*1000
values (about 999000 iteration if you start from 1000). so for that particular value alone, you are checking a number is a power of two about 1000000 times...
Now, how about just let k for 1 to 20 (so 2^k is already > 1000000), and calculate c, (2^k-ab) and check for only those 20 values of c.. (instead of 999000) times...
I will stop here (as obviously there can be more improvement).. but this is just a VERY small change ib
algorithm.. which improves the through about 50,000 times faster.. (*** Much Much faster in case where you reached say a=1000,000... in this case just this small change will improve 100 BILLION times!)
*** Background ***
Amber G. wrote:FWIW: This may be a question for algorithm dhaga.. but a VERY slight modification, even using brute force, can make the search thousands, -(if not millions) of time faster) .than it seems from above...chilarai wrote:yeah i did a quick and dirty one .its brute force search.
Added later , I could have made it about 6 times faster by having a<= b and b<= c , as of now all combinations are tested 6 times ( the number of permutations )Code: Select all
limit = 1000 l = [1..limit] is2power :: Integer -> Bool is2power = \x -> x `elem` ( map (2^) [0..30]) isfine :: Integer -> Integer -> Integer -> Bool isfine a b c = is2power ( a * b - c) && is2power (b * c - a) && is2power (c * a - b) res = [ ( a , b, c ) | a <- l , b <- l , c <- l , isfine a b c ]
(What I mean is that , (say to for limit=1000) the function is2power is called, about 3 times in each iteration
of 1000*1000*1000 times (well divide by 6 if you use a<=b<=c etc). Even considering is2power function is super fast, the process is hopeless for, say limit=1000000, because you are looking at 10^18 calls..A VERY slight change (How? - can others suggest how) can reduce this by a very huge factor
Hope this helps.
Re: BR Algorithms Corner
Thanks Amber G, yeah that helps. would be implementing it sometime. My aim to write the program was to see if i can find any patterns to the solutions and then try prove a generic solution by going backwards. But that does not seem likely with only the few ( and likely they are the only ) solutions found . So probably have to return back to algebraic manipulations .
added later : thanks again. With the modification, it could do 10,000 in less than 20 minutes. and the results are the ones already found
[(2,2,3),(2,2,2),(2,6,11),(3,5,7)] .
if anyones interested the prog looks like this now
added later : thanks again. With the modification, it could do 10,000 in less than 20 minutes. and the results are the ones already found
[(2,2,3),(2,2,2),(2,6,11),(3,5,7)] .
if anyones interested the prog looks like this now
Code: Select all
import Data.Bits
import Control.Monad
limit = 10000
l = [1..limit]
is2power :: Integer -> Bool
is2power x = ( x >= 1) && ( x .&. (x-1) == 0 )
isfine :: Integer -> Integer -> Integer -> Bool
isfine a b c = is2power ( a * b - c) && is2power (b * c - a) && is2power (c * a - b)
-- in the above can skip check for a*b -c because now it is fine by the construction
res = do
a <- [1..limit]
b <- [1..limit]
guard (a <= b )
c <- filter ( \x-> x>=1 && x <= limit) $ map (\x -> a* b - x ) $ takeWhile (< a*b) $ map (2^) [0..20]
guard (b <= c)
guard $ isfine a b c
return (a,b,c)
main = do
putStrLn $ show res
Re: BR Algorithms Corner
chilarai wrote:Thanks Amber G, yeah that helps. would be implementing it sometime. My aim to write the program was to see if i can find any patterns to the solutions and then try prove a generic solution by going backwards. But that does not seem likely with only the few ( and likely they are the only ) solutions found . So probably have to return back to algebraic manipulations .
added later : thanks again. With the modification, it could do 10,000 in less than 20 minutes. and the results are the ones already found
[(2,2,3),(2,2,2),(2,6,11),(3,5,7)]
<code omitted here> .
VERY nice and clear code. Thanks.
I am glad that was helpful. Actually I was thinking of keeping quite for about a month to see how things
go before commenting on anything related to that problem.. just to see how resourceful brf community is, hence gave a "hint onlee"..
So I am again not adding anything further at this point as not to "spoil the fun" except to comment that I did also try the "brute-force" method (just to put myself in the problem-solvers shoes).. to see how difficult or easy it could be. My method was quick and dirty (took me about 5 minutes to write and debug the code, and employed only the most basic logic) code was short quite similar to yours.. (BTW I REALY liked the simplicity of your code - and since it was short and clear, it was robust/bug_free).it did check all the numbers and found *all* correct solutions up to about the limit=1,000,000 as my first try running only for less than a minute.. Obviously I raised the limit for the second try to 100,000,000 and still found the run time only in minutes!..)... I am sure you will find out this can be done, so at present I am not posting my code but rest assured it is quite "simple" once you think about it..
Re: BR Algorithms Corner
For those wondering about my post a few posts above .. some background ..
x-post - About 2 weeks ago, I have posted a small challenge in brf_math dhaga (<link here>
to test the resourceful ness of brf community. I also believe those who like logical thinking will find the problem interesting.
x-post - About 2 weeks ago, I have posted a small challenge in brf_math dhaga (<link here>
to test the resourceful ness of brf community. I also believe those who like logical thinking will find the problem interesting.
Re: BR Algorithms Corner
I'm trying to understand 'face recognition algorithm(s)'. what is the main process/method to match two faces etc. and will that consider age related changes, bone mass changes, fat, wrinkles, etc?
Re: BR Algorithms Corner
In other dhaga ..
BTW.. this was exactly what I had in my mind when I said few posts above when I tried to put myself in "brute force solvers shoes"..
(Of course, another slight modification *may* improved the algorithm by a such an amount that even with slower cpu (and only only pen and paper ) one could try out whole thing in minutes..)..
) one could try out whole thing in minutes..)..
NICE!!chilarai wrote:I have yet another angle ( solution less ) , hope its not a repeat of something already discussed. sorry for my difference in notation .. of a , b and c for the numbers and i,j and k for the powers
so we have
ab - c = 2^i
bc -a = 2^j
re writing the two we have
b.a - c = 2^i
-a + b.c = 2^j
what we have is a two variable equation in a and c , ..solving for a and c we get
a = (b.2^i + 2^j) / ( b^2 -1)
c = (2^i + b.2^j)/(b^2 -1)
i wonder if we can use this somehow in the 3rd equation ca - b = 2^j to have any more insight .
BTW.. this was exactly what I had in my mind when I said few posts above when I tried to put myself in "brute force solvers shoes"..
Yes, my program was virtually identical..(though written in Rexx).. and was able to check numbers up to trillions..Amber G. wrote:My method was quick and dirty (took me about 5 minutes to write and debug the code, and employed only the most basic logic) .. I am sure you will find out this can be done, so at present I am not posting my code but rest assured it is quite "simple" once you think about it..
(Of course, another slight modification *may* improved the algorithm by a such an amount that even with slower cpu (and only only pen and paper
Re: BR Algorithms Corner
so finally got some time for coding . With the equations derived earlier and using shift operations instead of integer multiplications by 2 , now I can search up to 1,000,000 in less than 8 minutes . the code is
Code: Select all
import Data.Bits
import Control.Monad
limit = 1000000
powerlimit = ceiling $ logBase 2 (fromIntegral (limit * limit))
is2power :: Integer -> Bool
is2power x = ( x >= 1) && ( x .&. (x-1) == 0 )
res = do
b <- [2..limit]
j <- [0..powerlimit]
i <- [0..j]
let (a,ra) = quotRem num den
-- num = b * 2^i + 2^j
num = shift b i + shift 2 (j-1)
den = b*b -1
guard (ra == 0)
guard ( a <= b && a > 1)
let (c,rc) = quotRem num2 den2
-- num2 = 2^i + b*2^j
num2 = shift 2 (i-1) + shift b j
den2 = b*b -1
guard (rc == 0)
guard ( b <= c)
guard (is2power (a * c - b))
return( a, b, c)
main = do
putStrLn $ show res
Re: BR Algorithms Corner
Magic Square using Narayana Pandita's Folding method in Clojure
www.youtube.com/watch?v=Zj9IHlTQFpY
(def mulapankti [ 1 2 3 4])
(def parapankti [ 0 1 2 3 ])
(defn sum [li] (reduce + li))
(defn guna [S]
(/ (- S (sum mulapankti)) (sum parapankti))
)
(defn msquare [S]
(let
[
g (guna S)
dparapankti (map #(* %1 g) parapankti)
fl (vector (first mulapankti) (last mulapankti))
m (vector (second mulapankti) (nth mulapankti 2))
f (reverse (take 2 dparapankti))
l (take-last 2 dparapankti)
r1 (concat m m)
r2 (concat fl fl)
r3 (concat f l)
r4 (concat l f)
covered [r1 r2 (reverse r1) (reverse r2)]
coverer [r3 r4 r3 r4]
]
;fold covered and coverer
(for [i (range 0 (count parapankti))] (map #(+ %1 %2) (nth covered i) (nth coverer i)) )
)
)
(msquare 70)
;output
; (
; (12 3 22 33)
; (21 34 11 4)
; (13 2 23 32)
; (24 31 14 1)
; )
www.youtube.com/watch?v=Zj9IHlTQFpY
(def mulapankti [ 1 2 3 4])
(def parapankti [ 0 1 2 3 ])
(defn sum [li] (reduce + li))
(defn guna [S]
(/ (- S (sum mulapankti)) (sum parapankti))
)
(defn msquare [S]
(let
[
g (guna S)
dparapankti (map #(* %1 g) parapankti)
fl (vector (first mulapankti) (last mulapankti))
m (vector (second mulapankti) (nth mulapankti 2))
f (reverse (take 2 dparapankti))
l (take-last 2 dparapankti)
r1 (concat m m)
r2 (concat fl fl)
r3 (concat f l)
r4 (concat l f)
covered [r1 r2 (reverse r1) (reverse r2)]
coverer [r3 r4 r3 r4]
]
;fold covered and coverer
(for [i (range 0 (count parapankti))] (map #(+ %1 %2) (nth covered i) (nth coverer i)) )
)
)
(msquare 70)
;output
; (
; (12 3 22 33)
; (21 34 11 4)
; (13 2 23 32)
; (24 31 14 1)
; )
Was attending our local code enthusiasts club (sadly I was the only SDRE there) and one of the guys was talking about Monte Carlo methods and simulations and he gave an example using Excel and running business simulations in purchasing a local orchard (and determining if it is a worthwhile investment or not). He was supposed to write code in perl as well, but couldn't do it before the presentation started. While he was explaining the concept and the various graphs to the other people, I pumped out a real small example in perl which made a lot more sense to the guys present. Figure I might as well present it here, as an example of the Monte Carlo method.
First, we must understand what Monte Carlo method is. There are several problems that it is complicated to get an understanding of analytically, because of the possibility of a variety of input variables. However, the problem may be such that given a set of inputs, it is relatively easy to compute the end result. In general, the Monte Carlo method solves the problem as follows:
1. If not possible to determine what all the possible inputs are, determine the ranges of the different inputs. For instance, we may estimate that we can grow somewhere between 280 to 320 lemon trees per acre of land every year, each tree produces between 900 to 1200 lemons annually and the selling price of lemons ranges from $2.75 - $3.25 per 10 lemons.
2. Generate random numbers that fall within the ranges determined in step 1. Make sure that the random numbers follow a distribution similar to that which is observed for those numbers in real life.
3. Plug the generated random numbers into the equations, compute the result and see what fraction of the random numbers generated satisfy some property. This allows for predicting answers which are pretty close to observed results. The more the number of randomized inputs, the better the estimation is.
In our case, we will consider a circle which is inscribed inside a square.

Let the circle have radius r. Therefore, side of the square is equal to the diameter of the circle (i.e.) 2*r.
Now we know that area of the circle = A1 = pi * r^2
and area of the square = A2 = (2*r) ^ 2 = 4 * r^2
Therefore, ratio of A1 :: A2 = pi :: 4
or, by rearranging the equation slightly:
pi = 4 * A1 / A2
Now, let's say we draw our figure over a sheet of graph paper:

All we need to do is count the number of points inside the circle and the number of points inside the square (remember, any points inside the circle are also inside the square). Then, we can plug these counts as A1 and A2 in the equation above and we will get an approximation of pi.
To get a better approximation of pi, we can make the points smaller and finer. Of course, this may lead to a more accurate answer, but we will have to count more points now. Surely we don't want to evaluate every single possible point as the number of points is infinite. So what do we do then? The answer lies in generating a random set of points and evaluating them.
One way to imagine this is to assume that we have thrown a bunch of sand over our figure. All we have to do is compute how many sand grains fall inside our circle (A1) and the total number of sand grains (A2) and we will get an approximation of pi. This is what we will attempt to simulate.
Also, while we are at it, if we only consider one quadrant of the above figure, the ratio still remains unchanged (i.e.)
pi = 4 * A1/A2

So that is how we will proceed. We will generate random pairs of x and y coordinates and see if the points fall within the circle or not. So how do we compute whether a point is within the circle or not. One way is by using the distance formula we learned in middle school when learning analytical geometry. Basically, the formula states that given two points (x1, y1) and (x2, y2), the distance between the two points:
distance = sqrt( (x2 - x1)^2 + (y2 - y1)^2 )
Now in the figure above, assume that the center of the circle (i.e. the lower left coordinate of the square) is at 0,0. Therefore x1 = 0, y1 = 0. Then the distance of any coordinate point (x, y) from (0,0) works out to:
distance = sqrt( (x - 0)^2 + (y - 0) ^ 2) = sqrt(x^2 + y^2).
Or, if we square both sides, we get:
distance^2 = x^2 + y^2
As long as this distance is less than or equal to the radius of the circle (r), we know that the point (x, y) lies inside the radius of the circle. If the distance is > r, then we know that the point (x, y) lies outside the circle.
Now for the fun part. Assume that the side of the square is 1 unit (i.e.) the radius of the circle is also 1 unit. Then the ranges of x and y will be 0 <= x <= 1 and 0 <= y <= 1. So we can generate random numbers between 0 and 1 for x and y and then compute the distance from the origin point as x^2 + y^2. If this sum is less than 1^2 (i.e.) 1, then we know that x, y lies within the circle. If it is greater than 1^2 (i.e.) 1, we know it lies outside the circle.
So this is where we will go back to the principles of the monte carlo simulation:
1. We have determined our input variables as x and y and we have also determined the ranges of our inputs as (0 <= x <= 1) and (0 <= y <= 1). So we can generate sets of random points (x, y) within these ranges.
2. We can compute the distance of (x, y) from the origin as distance^2 = x^2 + y^2.
3. Since we know that our circle is of radius 1 unit, therefore any distance > 1 is outside the circle and any distance <=1 is inside our circle.
4. So we just generate a bunch of x, y coordinates and count how many times we fall inside the circle and count the total # of points (which all fall inside the square, since we are guaranteed this by constraining the min/max values of x and y)
5. Compute pi = 4 * (# of points inside circle) / (total # of points).
Writing the code in python, we have:
You can implement the same algorithm in any language that you're comfortable with. Note that the random.random() function in python doesn't exactly return a random number between 0 and 1 (inclusive), but returns a number between 0 and 0.999999999.... (i.e. something a little less than 1). Most other programming languages have random functions that return similar values like this (i.e. between 0 and something slightly less than 1). However, this is accurate enough for our purposes.
In the above code, note that I set the num_samples to 1000. You can change it to a larger or a smaller number to get a different approximation of pi.
Running it multiple times with num_samples = 1000, we have:
Now, changing the num_samples = 10000 and running it multiple times, we have:
and changing the num_samples = 1000000 and running it multiple times, we have:
As you can see, by increasing the number of samples, we start getting a better approximation of pi.
Hope this gives you guys a feeler for what Monte carlo simulations are all about.
Yensoy maadi.
First, we must understand what Monte Carlo method is. There are several problems that it is complicated to get an understanding of analytically, because of the possibility of a variety of input variables. However, the problem may be such that given a set of inputs, it is relatively easy to compute the end result. In general, the Monte Carlo method solves the problem as follows:
1. If not possible to determine what all the possible inputs are, determine the ranges of the different inputs. For instance, we may estimate that we can grow somewhere between 280 to 320 lemon trees per acre of land every year, each tree produces between 900 to 1200 lemons annually and the selling price of lemons ranges from $2.75 - $3.25 per 10 lemons.
2. Generate random numbers that fall within the ranges determined in step 1. Make sure that the random numbers follow a distribution similar to that which is observed for those numbers in real life.
3. Plug the generated random numbers into the equations, compute the result and see what fraction of the random numbers generated satisfy some property. This allows for predicting answers which are pretty close to observed results. The more the number of randomized inputs, the better the estimation is.
In our case, we will consider a circle which is inscribed inside a square.
Let the circle have radius r. Therefore, side of the square is equal to the diameter of the circle (i.e.) 2*r.
Now we know that area of the circle = A1 = pi * r^2
and area of the square = A2 = (2*r) ^ 2 = 4 * r^2
Therefore, ratio of A1 :: A2 = pi :: 4
or, by rearranging the equation slightly:
pi = 4 * A1 / A2
Now, let's say we draw our figure over a sheet of graph paper:
All we need to do is count the number of points inside the circle and the number of points inside the square (remember, any points inside the circle are also inside the square). Then, we can plug these counts as A1 and A2 in the equation above and we will get an approximation of pi.
To get a better approximation of pi, we can make the points smaller and finer. Of course, this may lead to a more accurate answer, but we will have to count more points now. Surely we don't want to evaluate every single possible point as the number of points is infinite. So what do we do then? The answer lies in generating a random set of points and evaluating them.
One way to imagine this is to assume that we have thrown a bunch of sand over our figure. All we have to do is compute how many sand grains fall inside our circle (A1) and the total number of sand grains (A2) and we will get an approximation of pi. This is what we will attempt to simulate.
Also, while we are at it, if we only consider one quadrant of the above figure, the ratio still remains unchanged (i.e.)
pi = 4 * A1/A2
So that is how we will proceed. We will generate random pairs of x and y coordinates and see if the points fall within the circle or not. So how do we compute whether a point is within the circle or not. One way is by using the distance formula we learned in middle school when learning analytical geometry. Basically, the formula states that given two points (x1, y1) and (x2, y2), the distance between the two points:
distance = sqrt( (x2 - x1)^2 + (y2 - y1)^2 )
Now in the figure above, assume that the center of the circle (i.e. the lower left coordinate of the square) is at 0,0. Therefore x1 = 0, y1 = 0. Then the distance of any coordinate point (x, y) from (0,0) works out to:
distance = sqrt( (x - 0)^2 + (y - 0) ^ 2) = sqrt(x^2 + y^2).
Or, if we square both sides, we get:
distance^2 = x^2 + y^2
As long as this distance is less than or equal to the radius of the circle (r), we know that the point (x, y) lies inside the radius of the circle. If the distance is > r, then we know that the point (x, y) lies outside the circle.
Now for the fun part. Assume that the side of the square is 1 unit (i.e.) the radius of the circle is also 1 unit. Then the ranges of x and y will be 0 <= x <= 1 and 0 <= y <= 1. So we can generate random numbers between 0 and 1 for x and y and then compute the distance from the origin point as x^2 + y^2. If this sum is less than 1^2 (i.e.) 1, then we know that x, y lies within the circle. If it is greater than 1^2 (i.e.) 1, we know it lies outside the circle.
So this is where we will go back to the principles of the monte carlo simulation:
1. We have determined our input variables as x and y and we have also determined the ranges of our inputs as (0 <= x <= 1) and (0 <= y <= 1). So we can generate sets of random points (x, y) within these ranges.
2. We can compute the distance of (x, y) from the origin as distance^2 = x^2 + y^2.
3. Since we know that our circle is of radius 1 unit, therefore any distance > 1 is outside the circle and any distance <=1 is inside our circle.
4. So we just generate a bunch of x, y coordinates and count how many times we fall inside the circle and count the total # of points (which all fall inside the square, since we are guaranteed this by constraining the min/max values of x and y)
5. Compute pi = 4 * (# of points inside circle) / (total # of points).
Writing the code in python, we have:
Code: Select all
#!/usr/bin/python
# Monte carlo simulation for pi by Armen Tanzarian.
import random
def run_simulation(num_samples):
count = 0
for i in range(num_samples):
x = random.random() # Gets a number in range 0..1
y = random.random() # Gets a number in range 0..1
# See if this point falls within the circle or not.
if (x ** 2 + y ** 2) <= 1:
count += 1
return count
num_samples = 1000
points_in_circle = run_simulation(num_samples)
print "pi = ", (4.0 * points_in_circle / num_samples)
In the above code, note that I set the num_samples to 1000. You can change it to a larger or a smaller number to get a different approximation of pi.
Running it multiple times with num_samples = 1000, we have:
Code: Select all
pi = 3.168
pi = 3.236
pi = 3.104
...
Code: Select all
pi = 3.1472
pi = 3.1436
pi = 3.1556
...
Code: Select all
pi = 3.142464
pi = 3.141408
pi = 3.141644
...
Hope this gives you guys a feeler for what Monte carlo simulations are all about
Yensoy maadi.
Last edited by ArmenT on 18 Sep 2015 06:22, edited 1 time in total.
-
Theo_Fidel
Re: BR Algorithms Corner
ArmenT, Thank you for that. Makes for fascinating reading. Definitely filing for use later with you permission. Two points.
1. You have left your full name in the code script.
2. One thing I would make clearer is that Base 0,0 is the center of the circle and not bottom left of big square.
1. You have left your full name in the code script.
2. One thing I would make clearer is that Base 0,0 is the center of the circle and not bottom left of big square.
Re: BR Algorithms Corner
Thank you much sir.
1. That's not my *real* full name (or even close to my name), just my nom-de-plume.
2. Yep, base (0,0) is center of the circle and also just happens to be the bottom left of the enclosing square of the quadrant.
Thank you again for the feedback sir. Much appreciated.
1. That's not my *real* full name (or even close to my name), just my nom-de-plume.
2. Yep, base (0,0) is center of the circle and also just happens to be the bottom left of the enclosing square of the quadrant.
Thank you again for the feedback sir
Re: BR Algorithms Corner
BTW the above is one example where a pseudo random number generator is just as good as a true random number generator.
Re: BR Algorithms Corner
I modified the post above slightly, to add in Theo's observations and clarify a couple of other things (like the random number generator returning between 0 and 0.99999999... rather than between 0 and 1). Hope it makes a bit more sense now.
Re: BR Algorithms Corner
So how fast does the above MC algorithm converge to the correct ( - well that is the first problem - what is "correct" for transcendental numbers? But let us not digress) of $/Pi$? Looking up the name "Metropolis" and "Las Vegas" would be instructive, I suppose.
How to integrate an n-dimensional function, namely f(x_1, x_2, ..., x_n) (say we need to find the volume of an n-dimensional body - let us limit ourselves to a small n)? What is the error if we use the MC (one wonders whether it can be used in this situation) for integration?
How to integrate an n-dimensional function, namely f(x_1, x_2, ..., x_n) (say we need to find the volume of an n-dimensional body - let us limit ourselves to a small n)? What is the error if we use the MC (one wonders whether it can be used in this situation) for integration?
Re: BR Algorithms Corner
sounds like a specialization of the general algorithm.But they also present a new method for applying their general algorithm to specific problems, which yields huge efficiency gains — several orders of magnitude.
http://news.mit.edu/2015/faster-optimiz ... rithm-1023
but what the heck is this from layman speak?
-
Bade
- BRF Oldie
- Posts: 7212
- Joined: 23 May 2002 11:31
- Location: badenberg in US administered part of America
Re: BR Algorithms Corner
The only structure with a good coat of paint always in the IITM campus...and you call it elite.
https://sites.google.com/site/swamiswaminatha/GC.jpg
https://sites.google.com/site/swamiswaminatha/GC.jpg
{kind=link}
Re: BR Algorithms Corner
Teradeep general object classifier This is what a state-of-art neural network for robotic vision can do: 1000 categories, 10 M images with full caption
Re: BR Algorithms Corner
I want to generate 8 billion test-data names. readable enough but not mandatory. combinations of letters is fine. say, if have first.middle initial.last pattern, I can get 26 inglicks letters for the middle. then I need to think of generating first and last. Is there a better way I can generate some nice readable names? Say, if I use the middle as variable to iterate, and have a well defined map of first and last that I can pick from at random or in sequence, such that it is unique for 8 billion names. How many first and last I need?
Is there a better way to do this?
Is there a better way to do this?
Re: BR Algorithms Corner
SaiK: first generate first names, last names, sort both lists eleminate duplicates, middle has 26 letters now do a cross product of all the three lists. You should do it in memory if you want it to be fast.
You need first and last name though from some source, may be a telephone directory or some marketing list.
You need first and last name though from some source, may be a telephone directory or some marketing list.