Amber G, appreciate the parichay

. I responded to a post by Ambar (I thought) and that turned out to be you. Then my previous post was a response to you (I thought), some time later when I looked at the post, it said "Ambar wrote" at the top - that's what the outburst was about. As for amar_p - that's a name which the admin gave him, because the admin thought his initial choice of name referred to a no-SQL database....
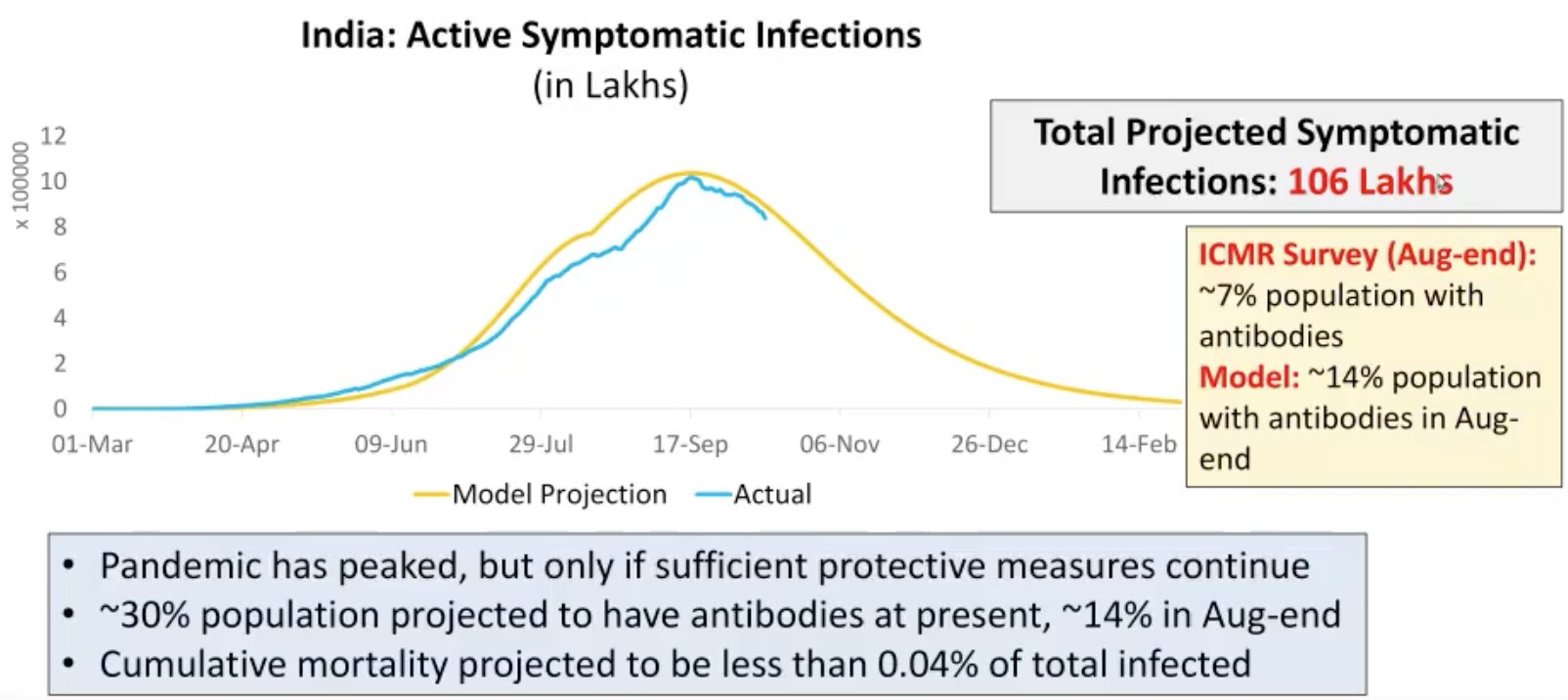
Anyways, about the SAIR model, some comments:
The model needs an initial state, right? That video in the math dhaga covers that in better detail (where the guy sets a variable to be 1, which represents the full population and also assumes initial values for S, I, R).
Why not just difference the model, why solve the differential equation (analytically, I think is what you were suggesting)? It could be differenced with a time step of 1 day, since that's the reporting period for all countries. Then it would be kind of like a Markov model, but not really, since there are some terms with products of different states (like SI*(A+I)). This would be a lot easier for somebody who wasn't that familiar with diff. eqns, or who was intimidated by them.
The parameters (beta, gamma, etc.) reported in the Supermodel site don't seem to have units, I'm guessing those are on "per day" bases.
The parameter epsilon seems pretty unrealistic. They report 1/eps=1000 for phase 1. That means (roughly) that for every infected (and symptomatic) person, there would be 1000 asymptomatic persons? Is the ratio that high? Even for phase 3, 1/eps was reported to be like 64, which means (roughly) 98.5% of infections are asymptomatic, and only about 1.5% actually develop symptoms? Or is epsilon only required for the initial state setup (I saw that it referred to SI_0 and SA_0)?
When you said - "anybody can try the model out with their own data" I got a very wrong impression. I thought anybody could take their own timeseries data and feed it to some engine on the website, and the engine would infer the model parameters (maybe by least-squares fitting) and fit the entire data to that. That would be something, and would be much more lay-person friendly. But it would require some intelligence on the part of the engine to figure out different phases (inflection points) and fit different parameter sets for each phase. Whereas, I think what is being talked about, is that anybody can assume their own values of the parameters, and use the equations to derive timeseries output, which can be compared with actual data. That's not so lay-person friendly, but more mathematically-inclined folks would like that.
In any case, having the model out in the open should help to some extent against propaganda like hnair saar was saying - "Hindoo nationalist Modi employs right-wing 'scientists' to come up with pseudo-scientific predictions." Not that hard-boiled cases like the BBC would let that stop them, but some less loony outfits - maybe.